How Canonicalization Fixes Duplicate Content Issues


Duplicate content can really stir the pot in SEO, especially when identical or nearly identical content appears on multiple URLs without proper canonicalization. This leaves search engines scratching their heads.
What Duplicate Content Really Means
Duplicate content refers to sizable chunks of text that pop up on more than one URL—either within the same site or scattered across different websites. Usually, this sneaky issue happens by accident or due to some technical hiccup.
- The same content popping up across different URLs on one site like those www and non-www twins that can cause quite the headache
- Content copied or duplicated from other websites whether it’s syndicated articles or sadly outright plagiarized material
- Pages that only vary by a hair such as those using URL parameters for tracking or filtering—they are like different outfits with the same face underneath
- Printer-friendly or cached versions of a page that just double down on the main content instead of offering something fresh
- Dynamic URLs packed with session IDs or sorting options churn out pages almost identical to each other making you wonder if anything’s actually changing
Duplicate content can really throw a wrench in the gears for search engines trying to decide which page deserves the top spot. When multiple pages carry the same material, search engines often get stuck trying to figure out which one is the most relevant or valuable. This muddle can dilute important ranking signals like backlinks and user engagement — like spreading your attention too thin. It’s a tricky situation that can lead to lower overall visibility and in some cases penalties if search engines suspect any funny business.
What exactly does Canonicalization mean in plain English?
Canonicalization in SEO is all about picking a preferred or "canonical" URL when you’ve got several URLs showing pretty much the same content. This chosen URL then acts as the go-to version that search engines should index and rank. By signaling this preference, website owners give search engines a helpful nudge to combine link equity and ranking signals.
The simplest and most common way to handle canonicalization is by adding the rel="canonical" tag in the HTML header of a webpage.
Understanding How Canonicalization Works in Practice A Hands-On Look
When a search engine crawls your website it looks for any rel="canonical" tags on your pages. Once it finds this tag the crawler knows which URL is the canonical version and adjusts its indexing and ranking signals accordingly.
A website owner smartly adds a canonical tag that points to the preferred URL on all duplicate or very similar pages.
Search engine bots then crawl these pages and spot the canonical link element like a pro.
Once the bots catch on, they treat the canonical URL as the main authoritative version—no arguments there.
Indexing signals like backlinks, content relevance and user engagement tend to rally around the canonical URL, giving it some well-deserved spotlight.
Only the canonical URL makes it into search engine results, helping to keep pesky duplicate listings at bay.
The rel="canonical" tag is the most common way to tackle canonicalization, though there’s also the option of using HTTP headers where the server steps in to point out the preferred URL. You can also play your cards with sitemap entries that list the main URLs, or go the server-side route with 301 redirects to tidy up different URL versions.
Typical Duplicate Content Situations That Canonicalization Helps Untangle
- Multiple URLs point to the same e-commerce product because of different filters or sorting options users use
- Parameterized URLs are crafted for tracking campaigns or sessions and tailored to each visitor
- The subtle differences between the www and non-www versions of a site’s pages are sometimes confusing but usually harmless
- Variations exist between the HTTP and HTTPS versions where one is more secure and the other may linger in the background
- Print-friendly or paginated pages mostly show the same content in different layouts
An online store where a single product page can be accessed through different URLs slightly tweaked by tracking parameters or filter choices. Without canonical tags, search engines see each URL as a separate page which splits the ranking signals. By adding a canonical tag to all variants that points to the main product URL, you gather their authority into one big happy family.
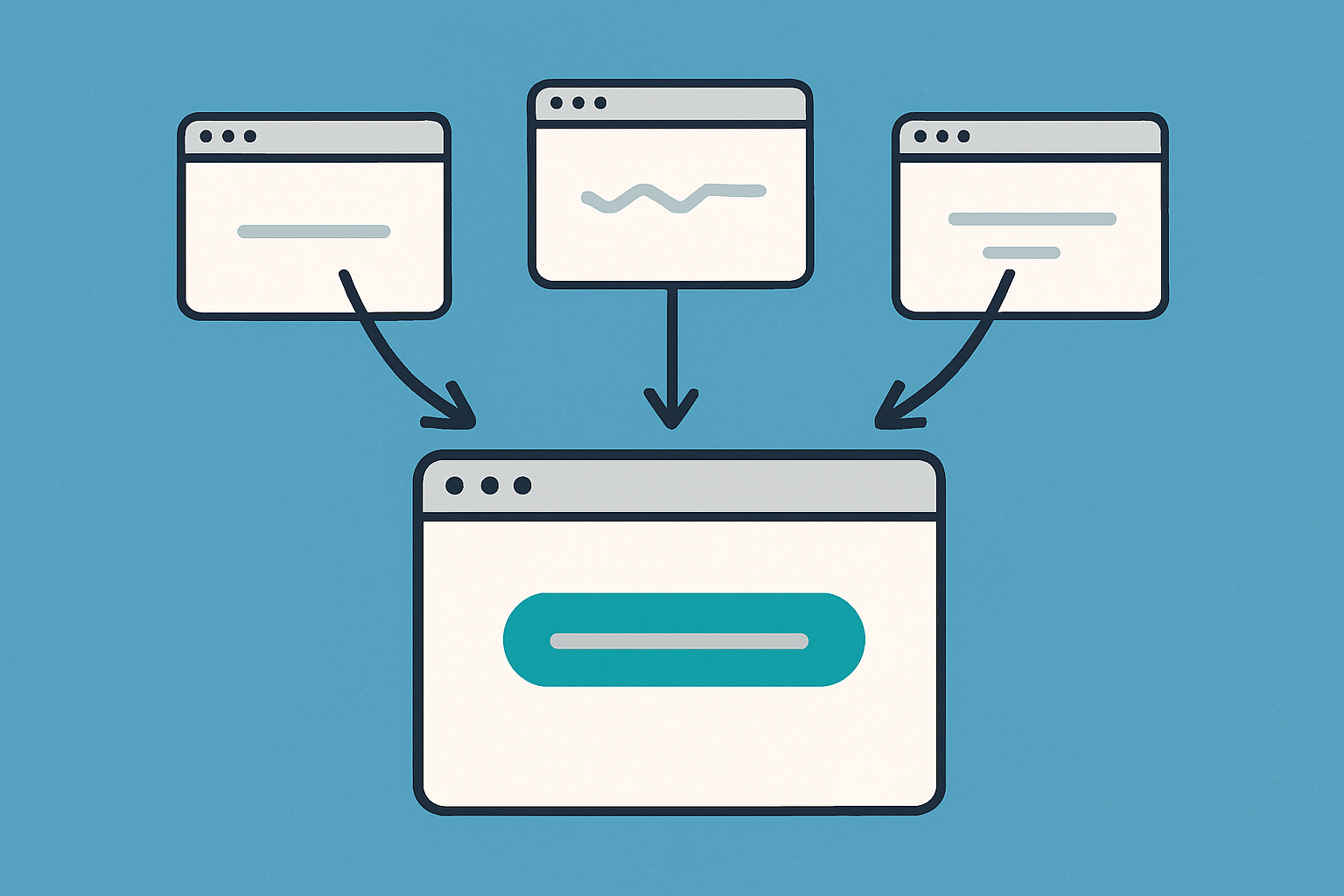
Visualization showing how canonical tags consolidate multiple similar URLs into one preferred version for search engines.
Key Guidelines for Implementing Canonicalization (the essentials you will not want to skip)
To get the most out of SEO with canonicalization it is vital to apply canonical tags with care—after all you don’t want search engines scratching their heads in confusion. That means staying consistent and double-checking that your canonical URLs are spot on. Also, make sure they align smoothly with the other SEO signals around your site.
- Always include self-referential canonical tags on your preferred pages to make clear which ones you want search engines to focus on
- Canonical tags should point only to exact duplicates or pages with very similar content, no guesswork
- Avoid building canonical chains or loops because they can cause crawling headaches later
- Use absolute URLs instead of relative ones in your canonical tags to keep things straightforward and avoid mix-ups
- Double-check that your canonical tags match the URLs in your sitemaps and robots.txt directives because consistency is key
Regularly testing and auditing your canonical tags using tools like Google Search Console or SEO crawlers such as Moz Pro or Mangools is pretty much essential if you want to keep things running smoothly and avoid any pesky surprises down the line.
Common Limits and Misunderstandings Around Canonicalization You Should Really Know
Canonicalization isn’t some magic wand that solves all SEO headaches caused by duplicate content. Canonical tags are more like friendly hints to search engines rather than strict commands. They don’t actually redirect visitors, and they don’t guarantee a page will get indexed either.
- Canonical tags by themselves won’t magically fix every SEO hiccup and really shouldn’t be leaned on as a quick fix to mask deeper content quality issues
- The canonical URL you set isn’t always the one search engines will go for if they pick up stronger hints pointing somewhere else
- Canonical tags aren’t a stand-in for good old-fashioned server-side 301 redirects when you want to steer traffic properly
- Canonicalization won’t sort out headaches caused by duplicate content pulled from other sites since plagiarism demands a whole different playbook
Canonicalization really shines when you team it up with other tactics like 301 redirects for permanent URL shifts, noindex meta tags for pages you want to keep under wraps from search engines and consolidating content to trim near-duplicates.
Why Canonicalization Really Matters for SEO Indexing
Duplicate content can really throw a wrench in your website's SEO efforts since it ends up confusing search engines and diluting those all-important ranking signals. Canonicalization gently nudges search engines toward the version of your pages you actually want them to pay attention to—kind of like a helpful lighthouse guiding ships to safe harbor. Bringing all that authority together not only tidies things up but also makes indexing a breeze.

Unlock Digital Marketing Success with Moz
Struggling to optimize your online presence? Moz is the ultimate Internet Marketing solution, empowering businesses with powerful SEO tools, insightful analytics, and expert guidance. Elevate your digital strategies and outshine the competition.
- Boost organic traffic with data-driven SEO tactics
- Enhance content marketing with expert recommendations
- Gain a competitive edge with comprehensive link analysis






